Authors: Egon Willighagen
The difference between a dataset and a database is not unlike food ingredients and a dinner. Databases are like the ready-to-eat dinners, sometimes in a fancy restaurant (read: the database has an application programming interface), sometimes at home (nice website). Datasets are what you need to cook the dinner, the ingredients. And like ingredients you want to have enough of them. Therefore, we archive datasets, so that we do not run out of them. Of course, datasets are digital and we can replicate them as often as we want.
To encourage the dissemination of open datasets in the NanoSafety Cluster, we started a catalogue of open datasets. The overview currently lists datasets from five projects (NanoPUZZLES, NANoREG, NanoCommons, NanoSolveIT and NanoCare) with three different open licenses (CCZero, CC-BY 4.0, and CC-BY-NC 4.0). The first dataset was released in 2015 and the most recent in 2021. The list will grow as we learn about more open datasets, and we are also thinking about keeping track of databases that utilise data from these datasets and present it in an easily usable format (as a digestible dish).
Technically, this overview is developed as a Markdown file in GitHub repository with embedded BioSchemas annotation, allowing Google Dataset Search to find the information about these datasets (and it does). Previously, a similar approach was used for getting tutorials listed in the ELIXIR TeSS database (see this article). We encourage other NanoSafety Cluster projects to also make their datasets more findable by creating such pages, or to contact the NanoCommons HelpDesk to have their datasets added directly to this list. Various tools exist to support the writing of such pages, including a validator. Figure 1 shows the validation results by Google. Lists of datasets with BioSchemas annotation can then be listed on the Live Deploys website at bioschemas.org/liveDeploys/.
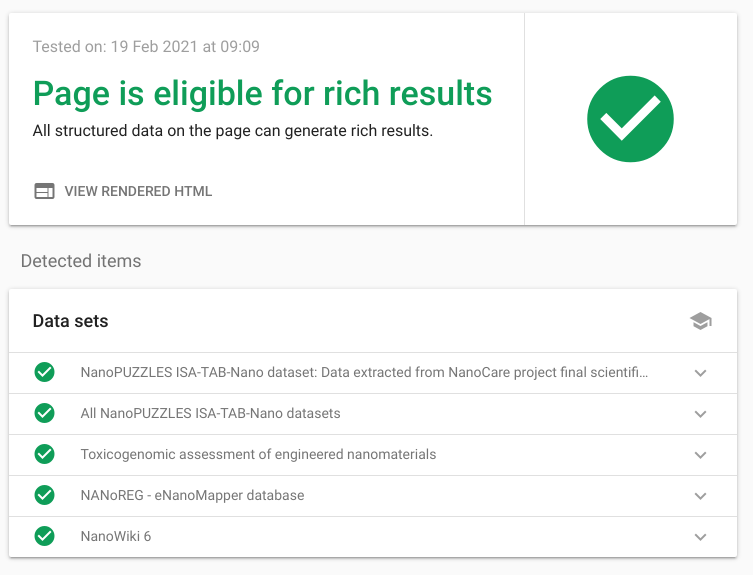
Figure 1: Screenshot of the current list of project-linked open datasets, verified by Google.
